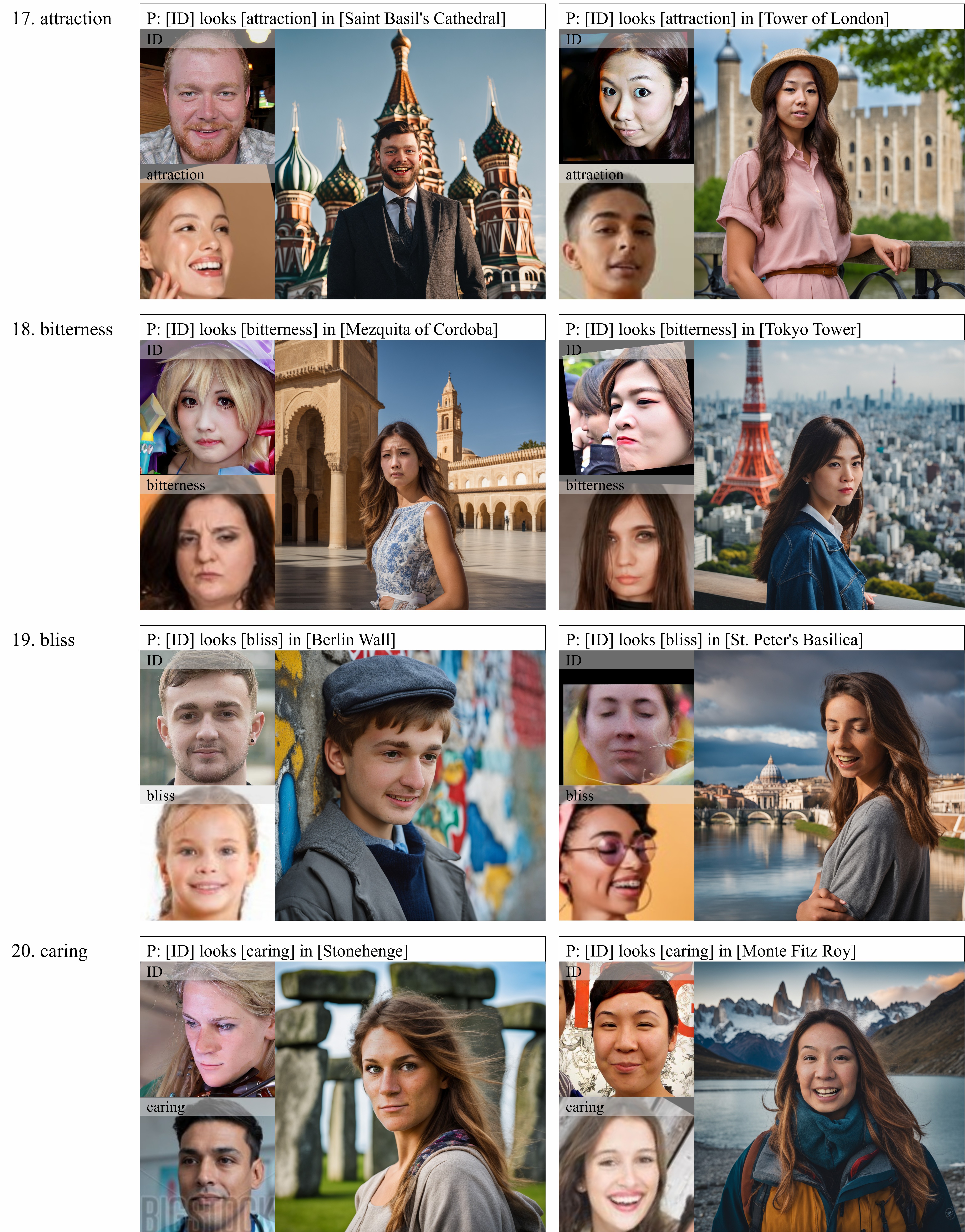
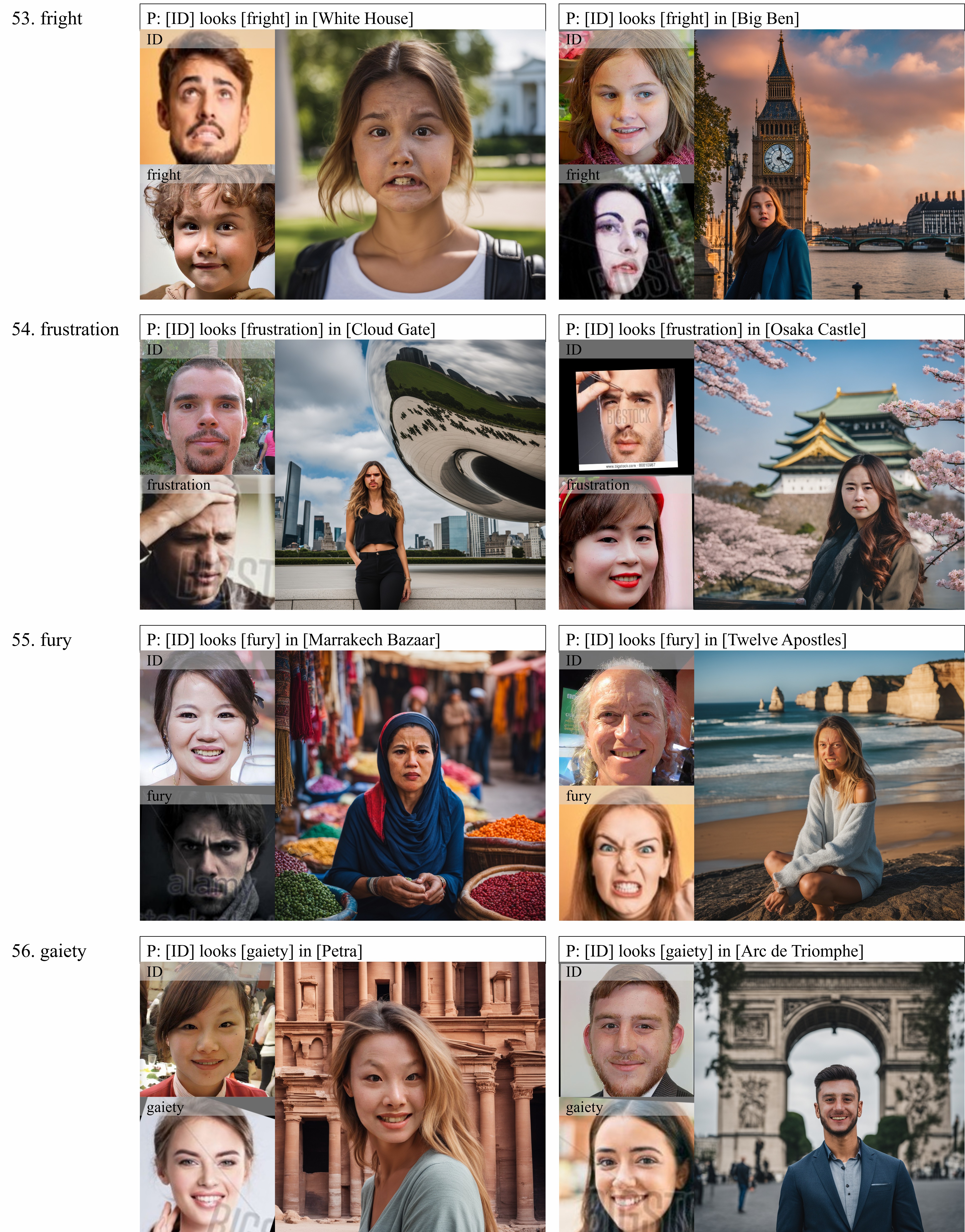
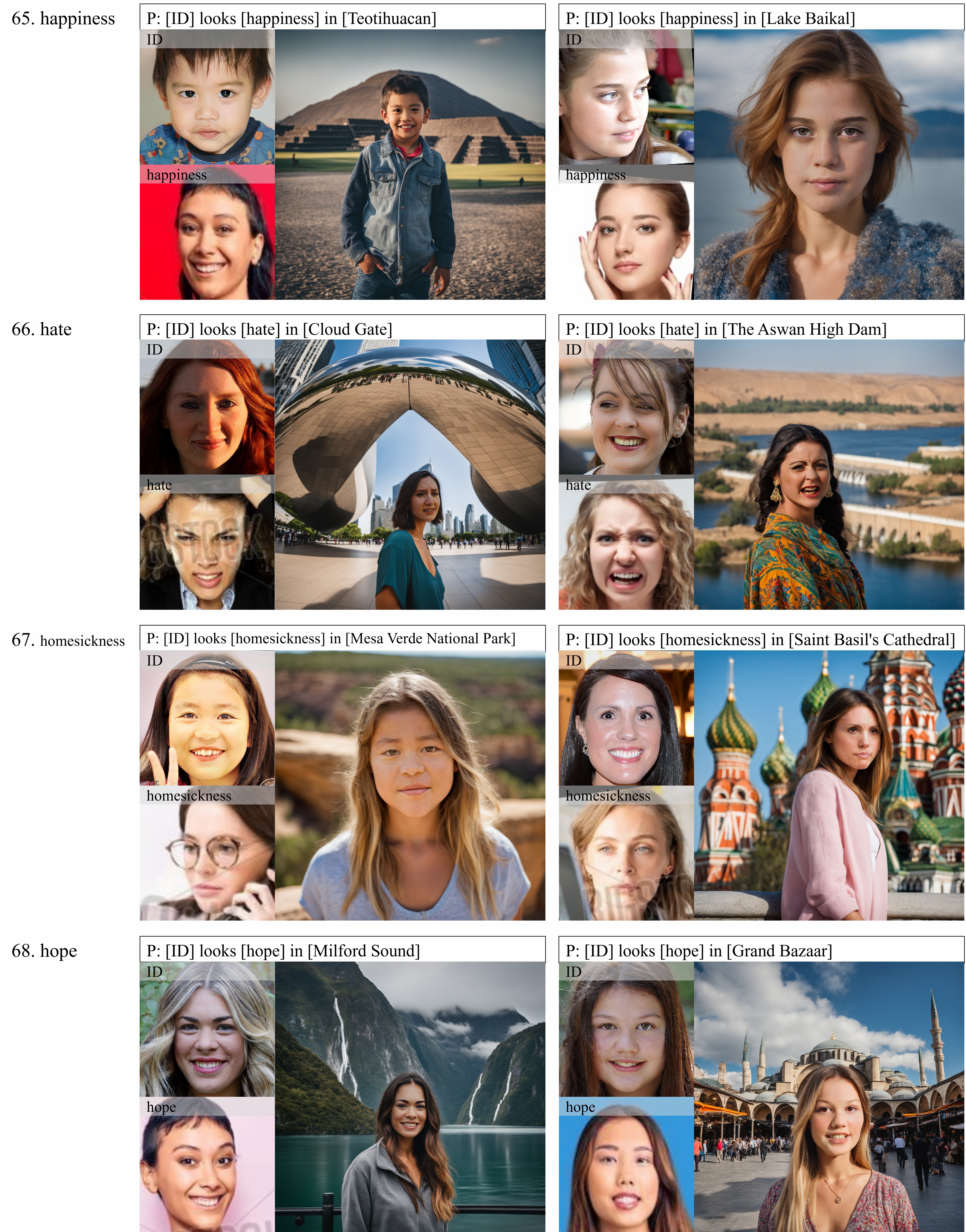
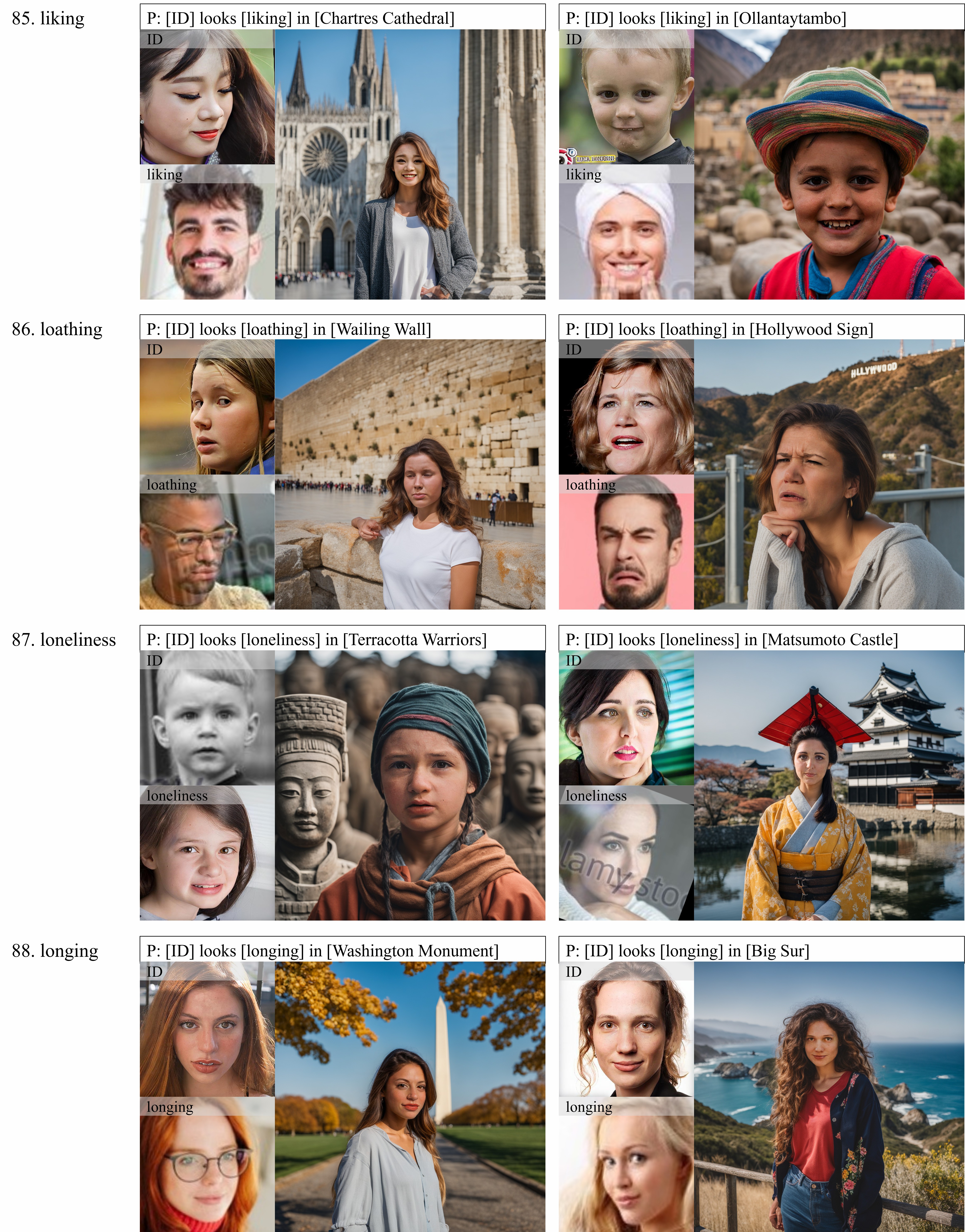
Qualitative
Here are some cases of sampling results. As shown above, Our results are not only more faithful to ground truth, but also more realistic and clear in the regions of eyes, mouths and even the reflection of sunglasses.



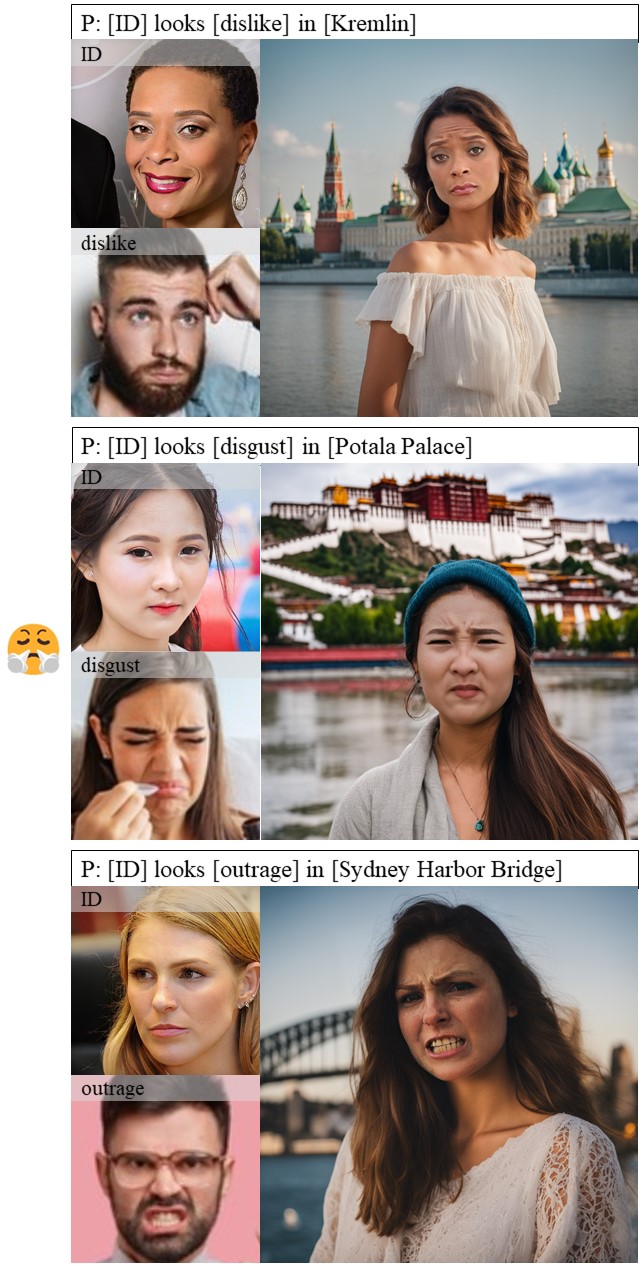
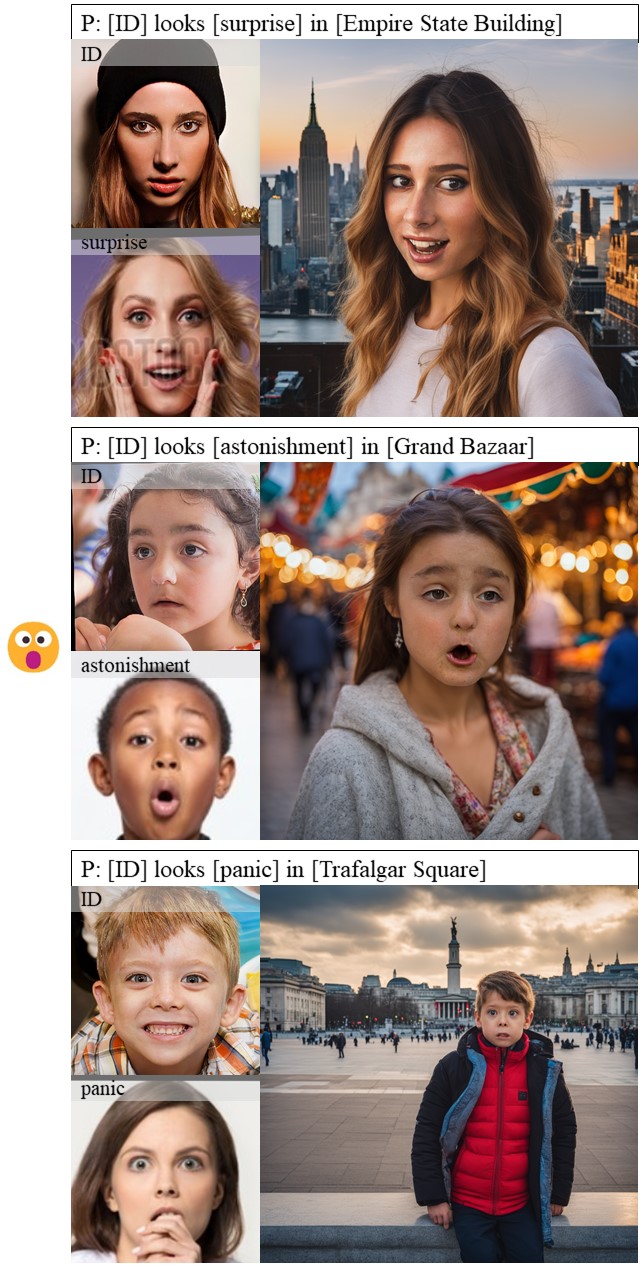
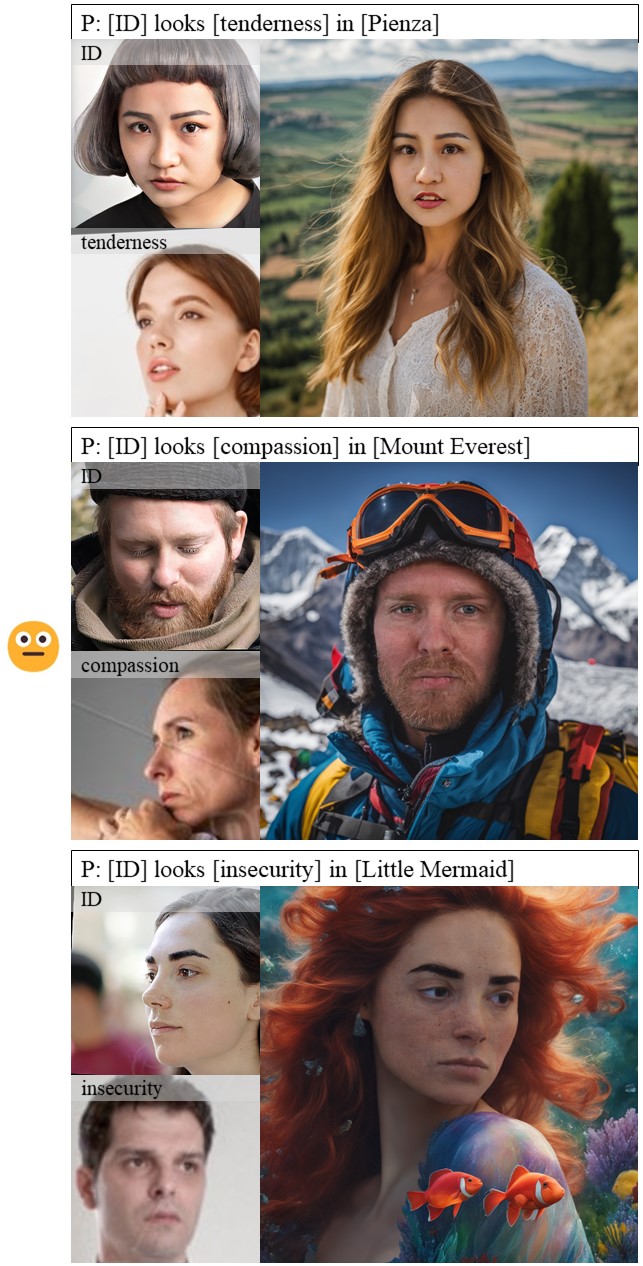
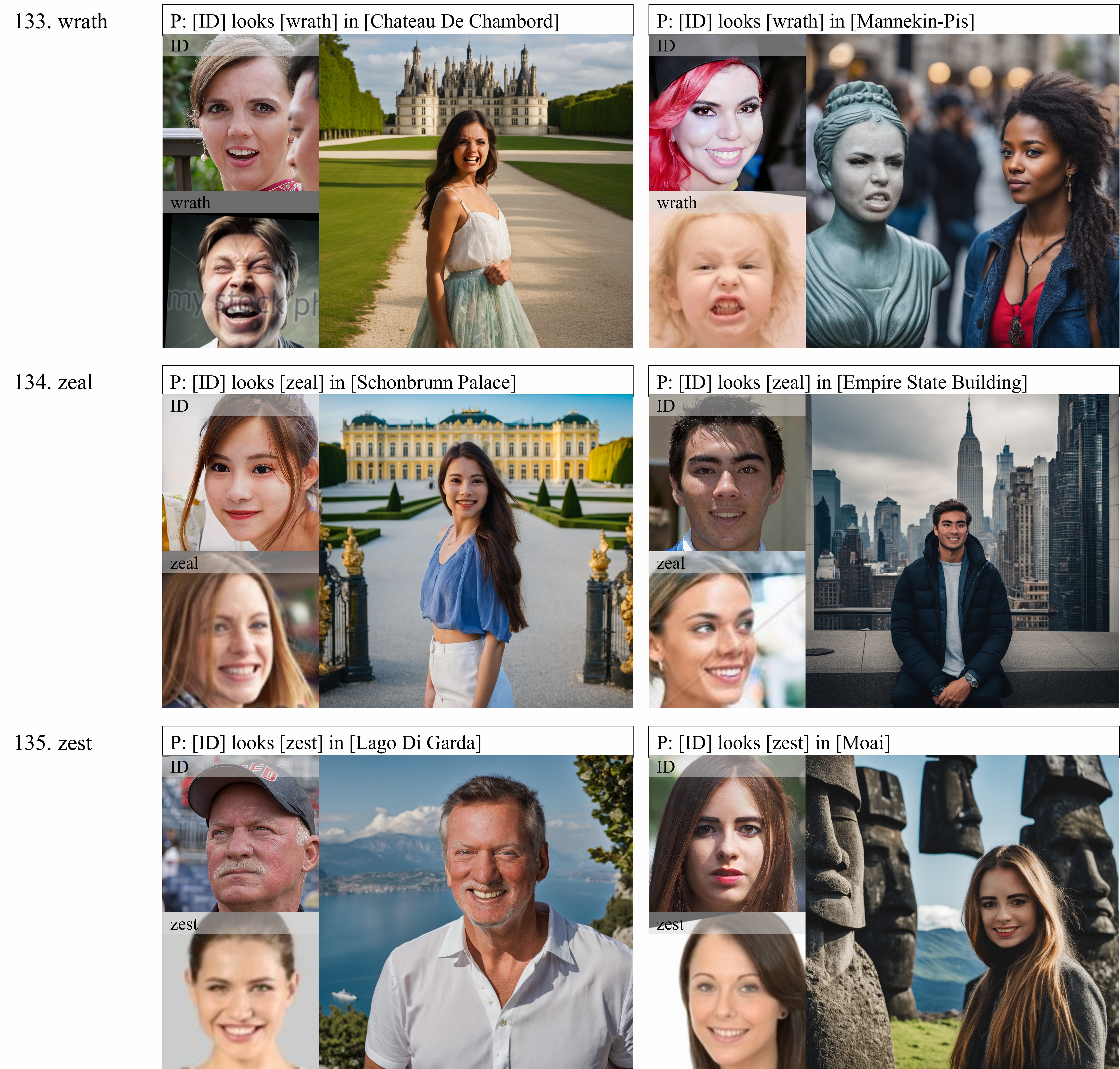
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions.
This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning.
Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.
DiffSFSR also supports expression travel by interpolating between embeddings to further explore fine-grained expression.

Start Frame

End Frame
Here are some cases of sampling results. As shown above, Our results are not only more faithful to ground truth, but also more realistic and clear in the regions of eyes, mouths and even the reflection of sunglasses.
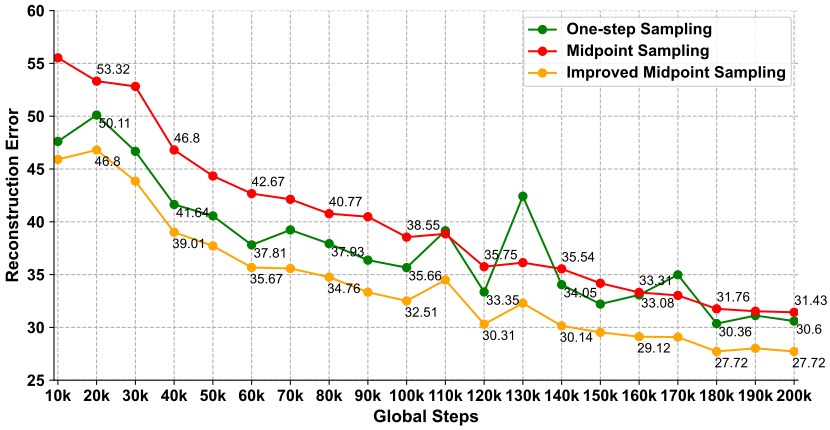
We employ MSE to measure the error between sampling results and ground truth. All sampling methods can decrease the reconstruction errors along with the training steps increasing. Our sampling method can achieve lower MSE than others in all periods.
@article{liu2024simultaneous,
title={Towards a Simultaneous and Granular Identity-Expression Control in Personalized Face Generation},
author={Renshuai Liu and Bowen Ma and Wei Zhang and Zhipeng Hu and Changjie Fan and Tangjie Lv and Yu Ding and Xuan Cheng},
journal={arXiv preprint arXiv:2401.01207},
year={2024}
}